
DiffRhythm – AI音乐生成器 扩散模型作曲神器 10秒创作人声伴奏完整歌曲
DiffRhythm介绍 DiffRhythm是一款基于扩散模型技术的AI音乐生成平台,让普通人也能秒变“音乐制作人”。只需输入歌词和风格提示(如流行、电子、古典),AI即可在10秒内生成带人声和伴奏的完整歌曲,最长支持4分45秒的专业级作...
DiffRhythm介绍 DiffRhythm是一款基于扩散模型技术的AI音乐生成平台,让普通人也能秒变“音乐制作人”。只需输入歌词和风格提示(如流行、电子、古典),AI即可在10秒内生成带人声和伴奏的完整歌曲,最长支持4分45秒的专业级作...

“AI 是人类智慧的结晶,它将帮助我们更好地理解和改善自己。”——Alan Turing,计算机科学先驱 “AI 不是要取代人类,而是要与人类共同创造更美好的未来。”——Sundar Pichai,谷歌 CEO “AI 的真正风险不是它的智...
覆盖全球160个国家和地区,整合现金供应链,快速响应,即时跨境物流保障,满足各类企业的日常需求,提供4000万条SKU选择,车间里常看到的工具、润滑油、油漆、焊材、磨料磨具、劳保用品、五金配件、运输工具、仓储设施等生产需要的辅助材料和消耗材料应有尽有!

准备文件:Docker Disk 、Ollama 、 MaxKB 1、Docker 安装 Docker 下载地址:www.docker.com 2、Ollama 安装 Ollama 下载地址:https://www.ollama.com 3...

最好用的整合包!持续更新中~ 求个关注加一键三连! 最近一次更新整合包是 【24年8月】不用担心,就是最新的! 直接下载就好了 拿了资源就给个关注吧,绝对是全网最好的整合包~ 拿完不会用?肯定还得回来看我的教程 ==============...
 选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。
选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。
| 客户端 | Windows | macOS | Linux | iOS | Android | 路由器 |
|---|---|---|---|---|---|---|
| Clash for Android | ✔ | |||||
| Clash for Windows | ✔ | ✔ | ✔ | |||
| ClashN | ✔ | |||||
| Clash Verge | ✔ | ✔ | ✔ | |||
| Clash Verge Rev | ✔ | ✔ | ✔ | |||
| ClashX | ✔ | |||||
| ClashX Pro | ✔ | |||||
| Clash Nyanpasu | ✔ | ✔ | ✔ | |||
| FlClash | ✔ | ✔ | ✔ | ✔ | ||
| Hiddify Next | ✔ | ✔ | ✔ | ✔ | ✔ | |
| NekoBox for Android | ✔ | |||||
| NekoRay | ✔ | ✔ | ||||
| OpenClash | ✔ | |||||
| PassWall2 | ✔ | |||||
| Potatso Lite | ✔ | |||||
| Quantumult | ✔ | |||||
| Quantumult X | ✔ | ✔ | ||||
| Shadowrocket | ✔ | |||||
| ShadowsocksR Plus+ | ✔ | |||||
| sing-box | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Stash | ✔ | ✔ | ||||
| Surfboard | ✔ | |||||
| Surge iOS | ✔ | |||||
| Surge Mac | ✔ | |||||
| v2rayN | ✔ | |||||
| v2rayNG | ✔ | |||||
| V2rayU | ✔ | |||||
| WinXray | ✔ | |||||

编辑原因: Adobe系列官方安装程序+破解补丁(目录下Crack文件夹)都在此文章更新,因Adobe直装版更新较慢! [04.01] Adobe Premiere Pro 2025 v25.2.0 破解版 Adobe Media Encoder 2025 v25.2.0 破解版 Adobe Audition 2025 v25.2.0 破解版 Adobe After Effects 2025 v25.2.0 破解版 [03.29] Adobe Illustrator 2025 v29.4.0 破解版 [03.27] Adobe Photoshop 2025 v26.5 破解版 Adobe Photoshop 2024 v25.12.2 破解版 [03.22] Adobe Animate 2024 v24.0.8 破解版 Adobe Animate 2023 v23.0.11 破解版 [03.20] Adobe Acrobat PRO DC v2025.001.20435 破解版 Adobe Bridge 2024 v14.1.6 破解版 [03.18] Adobe Bridge 2025 v15.0.3 破解版 [03.12] Adobe Substance 3D Modeler 1.21.0 破解版 Adobe Substance 3D Painter 11.0.0 破解版 [03.11] Adobe InCopy 2024 v19.5.3 破解版 Adobe InDesign 2024 v19.5.3 破解版 [03.06] Adobe InCopy 2025 v20.2 x64 破解版 Adobe InDesign 2025 v20.2 x64 破解版 [02.21] Adobe Substance 3D Designer 14.1.1 破解版 Adobe Substance 3D Sampler 5.0.0 破解版 [02.20] Adobe Illustrator 2024 v28.7.5 x64 破解版 [02.13] Adobe Lightroom Classic 2025 v14.2.0 破解版 Adobe Photoshop Lightroom v8.2 破解版 [01.29] Adobe Substance 3D Stager 3.1.1 破解版 Adobe Dimension 4.1.1 破解版因为一直被百度网盘取消分享,所以百度云的下载地址只提供原版(不包含PS,容易被和谐),破解补丁请移步此处: Adobe全家桶系列激活工具
「机型:」
「永久免费」两个 1h1g 的小鸡,十分适合建站用。
「地域推荐:」
地区极力推荐韩国春川、日本东京、大版、美国圣何塞、凤凰城。
「IP:」
有的 ip 段解锁奈飞(但是有个别的不能开arm,详情关注我,下次详说)
「硬盘空间:」
默认 45G,可以用作离线下载也不错,实际测试网络 48~60M(标记是0.48G~1G)每月共10T流量!
「地址:」
https://www.oracle.com/cloud/
「注意:」
注册不用挂梯子,一张自己的双币信用卡过验证即可,注册靠运气。新上永久免费 arm 机,配置最高可达 4H24G~
但是注意总共(amd 和 arm 加起来)的磁盘空间不能超过 200G,ipv4 数量不能超过 6 个。
所以一般最大上限是开两个 amd,两个 2h12g 的 arm,全部用默认分配的磁盘空间(或者 4 个 1h6g 的 arm 机)。
「总体情况:」
现在是免费薅「3个月」的试用,不升级付费不会额外扣款,300 美刀的免费试用
「节点推荐:」
G口,推荐使用香港地区
「地址:」
https://cloud.google.com/
「注意:」
必须要一张实体信用卡过验证,所以十分难薅,不过只要是自己的即可轻松过。
「支持支付宝」,使用充送优惠码「dominate2022」,充值10美元,最多账户获得30美元,10美元可用5个月,相当于不要钱。
更新:LightNode后台发起工单,发送关键字“LightNodeBest”获得礼品码。(亲测目前可用)
「节点推荐:」
拥有高质量香港CN2 GIA节点与原生IP(河内、曼谷、华盛顿、柬埔寨)。
「解锁流媒体:」
对于想用VPS解锁「Netflix、 TikTok」或者其他流媒体,以及对CN2有需求的都可以看看。
「官网地址:」
「具体测评:」
「免费一年」
虚拟卡可过,套路较多,特别容易产生扣费,建议多谷歌一下查看相关教程再薅
每月 15G 流量,所以一般是月抛,自己用不合算
「地址:」
https://aws.amazon.com/
「免费一年」
注意别开错了机子,不然也容易产生扣费,建议看一下我以前相关教程
免费 linux1 & windows1 动态 ip,b1s 机型,64G 硬盘存储是免费的
「注意:」
自己过信用卡验证是 200 刀首月免费,每月 15G,超出即扣费
学生 100 刀不用信用卡验证,需要过手机号验证,建议使用专业接码网站和学生邮箱账户,基本也是月抛
「地址:」
https://azure.microsoft.com/en-us/
「免费 120 天」
邮箱注册即可,不需要信用卡验证。
注册理由写明是学生等研究用途
「注意:」
容易触发风控,目前已知的封号原因:
脚本触发了 v2r*y、trojan 等关键词、 频繁删机重开、大流量占用
「地址:」
https://linuxone.cloud.marist.edu/#/login
「免费英国 VPS 一个月」
原生 IP 解锁奈飞。
「注意:」需要信用卡验证
「地址:」https://www.civo.com
「一个月」
「注意:」
需要信用卡,注册最多送 100 美元,充值多少送多少
「地址:」
「两个月」
注册免费送两个月有效的 100 刀,需要信用卡,配置 1H1G 等
「地址:」
https://www.linode.com/lp/brand-free-credit-short/
「理论免费」
纯 ipv6,面板可以很方便的添加 ipv4 配置 1H512M。
注册仅需一个 tg 账号,不用信用卡
「注意:」
理论永久免费,需要每周手动续订一下
「Ditital Ocean 200 美元使用免费vps」
Ditital Ocean需要信用卡或者 paypal Ditital Ocean注册送 200 美元,可以购买免费vps「Ditital Ocean免费vps注意事项:」
「Ditital Ocean官网地址:」
有学生邮箱的建议开通 GitHub 学生包然后用 DO 的激活码。
来激活免费的 100 刀,需要过信用卡验证
「GitHub 学生包:」
这个包里还有包括域名在内等其他很多免费学生专属福利
「萤光云免费香港cn2/福州高防云最长至1年」
「萤光云免费vps活动详情:」
“你搞技术,我出资源” 萤光云助力技术牛人
「萤光云免费vps活动地址:」
萤光云:活动地址
「萤光云节点推荐:」
萤光云香港cn2线路延迟低、0丢包;福州BGP高仿独享,测试过服务器性能都不错。
萤光云其他节点:北京/上海/台北/华盛顿/新加坡/土耳其/曼谷/河内/新加坡也可置换。
「萤光云免费vps注意事项:」
「Kamatera月免费vps」
任选配置,一个月免费vps,300 刀,试用代码 1MONTH300
「Kamatera免费vps注意:」
绑卡扣除 2 美刀验证,支持 +86 手机和 googlevoice 验证
「Kamatera配置选择:」
最高配置可选 40 核专用 CPU,512G 内存,4TB 固态,5T 流量(香港 1T),1G 带宽
CPU 类型 B 是通用型,性能一般。D 是专用型,性能最强。T 是突发型,性能较强。A 是可用型,性能最弱。
「Kamatera地区选择:」
可选美国(纽约、达拉斯、圣塔克拉拉)、加拿大(多伦多)、欧洲(阿姆斯特丹、法兰克福、伦敦)、以色列(皮塔赫。提克瓦、罗什。海因 1/2、特拉维夫、耶路撒冷)、中国(香港)等地区
香港并非三网直连,速度很慢,美国地区是很干净的原生 ip
「Kamatera地址:」
Kamatera官网「Yandex Cloud60 天的免费vps」
Yandex 云新注册用户赠送价值 4000 卢布 (大概 350 人民币)。
有效期 60 天的免费vps。
其中 1000 卢布用于云主机,3000 用于其他云计算服务
「Yandex Cloud官网地址:」
「Yandex Cloud注意:」
需要绑定银行卡,必须支持 3D 安全验证。
可以使用 yandex.money 虚拟卡,国家建议选俄罗斯。
「Evolution Host置换免费vps规则」
需要有一个有流利的博客才可申请免费vps,然后博客首页放上他们的广告即可白嫖
「Evolution Host免费vps注意事项:」
「Euserv网址:」
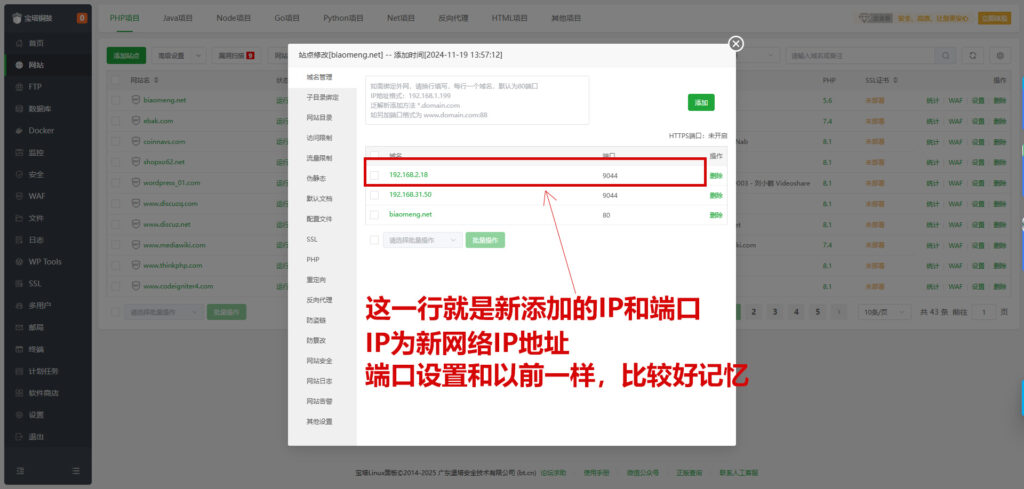 二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了
二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了X 网友语出惊人的调侃
隔行如隔山,虽然不能直接比较,但差距非常直观:OpenAI 2023 年化收入 16 亿美元,2023-2024 赛季 NBA 总薪水 49 亿美元。 OnlyFans 的成绩,不依赖广告金主,而是靠海量用户付费得来。 都说互联网的第一生产力是搞黄色,但这话多少带些「白嫖」的意味,爱看,但不一定愿意花钱。为什么这么多用户,心甘情愿地为 OnlyFans 掏出腰包?OnlyFans 创作者 Bryce Adams 订阅用户超过一百万
除了搞黄色,你也能在这里看到健身、烹饪、音乐等非十八禁的内容,甚至和明星说上话。 名人入驻 OnlyFans 有一个好处:自带光环和流量,不必以大尺度为噱头。 巴黎奥运会双人跳水铜牌得主 Jack Laugher,靠 OnlyFans 的副业,支撑自己的跳水事业——他的运动员薪水,只有每年 28000 英镑,哪怕在里约奥运会拿过冠军。Jack Laugher 的订阅价格是每月 10 美元
平时,Jack Laugher 发的都是一些穿着泳裤、三角内裤、平角内裤的内容,没有全裸。泳裤相当于职业装,所以他和他家人都觉得很自在,「没有什么是你不能给你奶奶看的」。 美国知名说唱歌手卡老师 Cardi B,也会在 OnlyFans 分享音乐幕后、个人生活,把它当成 Instagram 运营,只和粉丝联络感情,强调不会展示自己的胸部。就这,赚了 4500 万美元,2023 年在名人里排第二。OnlyFans 创作者也玩 cosplay
虽然 OnlyFans 总部在英国,但有数据显示,三分之二的收入来自美国,英国和欧洲用户占 16%,其余 17% 属于「世界其他地区」。 《OnlyFans 用户的性态度和特征》这篇论文,用户画像更加具体:OnlyFans 用户主要是已婚白人男性,平均年龄 29 岁,平均年收入 4.2 万美元。 怎么说,其实不让人意外,就像下班后在车里吸一根烟再上楼的国产剧男性形象。说唱歌手 Bhad Bhabie 最近晒单,2021 到 2024,她从 OnlyFans 赚到了 5700 万美元
2020 年,独立研究员 Tom Hollands 抓取了 OnlyFans 的支付数据,发现前 1% 的创作者赚了 33% 的钱,大多数创作者每月赚的钱不到 145 美元。 如果可以一年赚到 4.9 万美元,那么可喜可贺,已经跻身前 1% 了。 OnlyFans 二八分成,平台 20%,创作者 80%,听起来似乎很慷慨,但到创作者手里的,不一定全须全尾。一张著名的梗图,股市不如 OnlyFans 赚钱
这些机构吃着碗里,不忘看着锅里,还会物色新的对象,在 Instagram 邀请女性「下海」,话术是一起发财。 「在互联网上,没人知道你是一条狗」的笑话,永不过时。 这条生产链的底端,往往是那些外包的代聊,又称「chatter」。全球不缺廉价的英语劳动力,他们大多数是菲律宾、尼日利亚、印度等地的低薪工人,每周工作 6 天,连续工作 12 小时,时薪 3 美元,还不如在麦当劳做汉堡。 钱难赚,屎难吃,这份工不好打,精神压力很大,要听几百个人吐苦水、讲怪话,同时背负销售的 KPI。简单来说,就像客服一样。恰好,菲律宾也是世界呼叫中心之一。AI 陪聊产品,可以聊不同风格的
当 AI 发展起来,聊天机器人陪聊,成了解放人类劳动力的一种出路。甚至,这些聊天机器人可以基于过往的聊天记录训练,根据每个网红的风格量身定制。 不过,OnlyFans 禁止 AI 回复聊天。上有政策,下有对策,AI 写消息,人类点发送键,总体还是比以前更加高效,一个人就能负责几百个聊天对象。但很难说,是轻松了,还是更痛苦了。 OnlyFans 有审核,却也管不了这些 AI。在这个 Deepfake 已经很难肉眼辨认的时代,虽然在内部成立了 AI 团队,OnlyFans 依然由人工审核主导,但检查的主要是,有没有擦边的未成年内容。 作为一个系统,OnlyFans 无疑很成熟,拿捏住人性需求,从一开始就要求用户付费访问内容,形成了一个健康、稳固的付费生态。 马斯克的 X 也在尝试付费订阅,还放宽了对成人内容的限制,但 OnlyFans 首席执行官 Keily Blair,对其他平台的「OnlyFans 化」,并不看好。Keily Blair (右)
她的理由很简单,付费或者不付费,都是一种惯性。其他社交媒体的用户,已经习惯了内容是免费的。如果这些平台也想尝试订阅模式,就需要让用户觉得,内容是独家的,自己可以获得更多价值。 OnlyFans 把「干什么都要花钱」的路径走通了,任何一个环节都懂得怎么更快、更系统地攫取更多利益,但得到大部分利益的人,并不一定是创作者自己。OnlyFans 整的一个活,日历内页全是 Fan(风扇)而非性感的封面女郎
这本是为了防范违法行为,同时也起到了将 AI 拒之门外的效果。 然而,外面的世界,已经到处都是 AI 了。 聊天机器人尚且不影响 OnlyFans 的主营业务,因为聊天是增值,是钩子,用户最终会购买真人的图片和视频,但从头到脚都是 AI 的网红,可能会对 OnlyFans 本身造成冲击。 OnlyFans 近年的数据反映了一个很有趣的现象:订阅占总收入的比例减少,按次付费的比例增加,2023 年甚至占了近 60%,而且不算小额,一次几十美元或者更多。使用 Flux 生成的 AI 女性
若要论灵魂的共鸣,AI 虚拟伴侣也已经是一个非常火的赛道,Character AI、Talkie、星野,让你用 AI 二创真实人物,或者设定原创角色,外貌、性格、语音、故事线都能自定义。个性化体验,被推向了新的高度。 二、创建私人频道的前提条件
1.拥有一个Telegram账号:要创建私人频道,您需要先拥有一个Telegram账号。如果您还没有账号,可以通过Telegram官方网站或应用进行注册。
2.具备相应的权限:在创建私人频道之前,您需要确保自己具备相应的权限。通常,Telegram平台对管理员和频道创建者有一定的权限要求,您需要确保自己符合这些要求。
三、创建私人频道的步骤
1.打开Telegram应用程序:首先,打开您的Telegram应用程序。
2.点击右上角的“+”按钮:在应用程序的顶部菜单栏中,点击右上角的“+”按钮。
3.选择“创建频道”选项:在弹出的菜单中,选择“创建频道”选项。
4.输入频道的名称和描述:在创建频道的页面中,输入频道的名称和描述。这些信息将用于标识和描述您的频道。
5.选择频道的类型和隐私设置:根据您的需求,选择频道的类型(公开或私有)和隐私设置。如果您选择私有频道,您需要设置管理员和成员列表。
6.点击“创建”按钮完成创建:在设置完频道的各项参数后,点击“创建”按钮即可完成频道的创建。
四、私人频道的设置与管理
1.修改频道名称和描述:在频道创建完成后,您可以随时修改频道的名称和描述,以更好地描述和标识您的频道。
2.设置频道类型和隐私设置:您可以根据需要随时更改频道的类型和隐私设置,以满足您的需求。
3.添加频道管理员和成员:如果您设置了私有频道,您可以添加管理员和成员来管理频道的权限和内容。
4.移除频道管理员和成员:如果您需要调整频道的权限设置,您可以移除不再需要的频道管理员和成员。
5.退出频道管理员身份:如果您不再需要担任频道管理员,您可以退出管理员身份,以减少不必要的权限和责任。
五、邀请他人加入私人频道
1.生成邀请链接或二维码:如果您希望邀请他人加入您的私人频道,您可以通过生成邀请链接或二维码来邀请他们。这些链接或二维码可以让被邀请人直接加入您的频道。
2.发送邀请链接或二维码给他人:将生成的邀请链接或二维码发送给想要邀请的人。您可以通过电子邮件、社交媒体或其他渠道将链接或二维码发送给他人。
3.被邀请人接受邀请并加入频道:被邀请人收到链接或二维码后,可以通过点击链接或扫描二维码来接受邀请并加入您的私人频道。
六、注意事项
1.确保使用真实身份创建频道:为了保护个人隐私和信息安全,建议您使用真实身份创建私人频道。这将有助于确保您与他人之间的交流更加真实可靠。
2.注意保护个人隐私和信息安全:在创建和使用私人频道时,请注意保护个人隐私和信息安全。不要将敏感信息泄露给他人,并确保您的账户安全可靠。同时,也要注意遵守Telegram平台的使用规则和政策,确保您的行为符合平台要求。
二、创建私人频道的前提条件
1.拥有一个Telegram账号:要创建私人频道,您需要先拥有一个Telegram账号。如果您还没有账号,可以通过Telegram官方网站或应用进行注册。
2.具备相应的权限:在创建私人频道之前,您需要确保自己具备相应的权限。通常,Telegram平台对管理员和频道创建者有一定的权限要求,您需要确保自己符合这些要求。
三、创建私人频道的步骤
1.打开Telegram应用程序:首先,打开您的Telegram应用程序。
2.点击右上角的“+”按钮:在应用程序的顶部菜单栏中,点击右上角的“+”按钮。
3.选择“创建频道”选项:在弹出的菜单中,选择“创建频道”选项。
4.输入频道的名称和描述:在创建频道的页面中,输入频道的名称和描述。这些信息将用于标识和描述您的频道。
5.选择频道的类型和隐私设置:根据您的需求,选择频道的类型(公开或私有)和隐私设置。如果您选择私有频道,您需要设置管理员和成员列表。
6.点击“创建”按钮完成创建:在设置完频道的各项参数后,点击“创建”按钮即可完成频道的创建。
四、私人频道的设置与管理
1.修改频道名称和描述:在频道创建完成后,您可以随时修改频道的名称和描述,以更好地描述和标识您的频道。
2.设置频道类型和隐私设置:您可以根据需要随时更改频道的类型和隐私设置,以满足您的需求。
3.添加频道管理员和成员:如果您设置了私有频道,您可以添加管理员和成员来管理频道的权限和内容。
4.移除频道管理员和成员:如果您需要调整频道的权限设置,您可以移除不再需要的频道管理员和成员。
5.退出频道管理员身份:如果您不再需要担任频道管理员,您可以退出管理员身份,以减少不必要的权限和责任。
五、邀请他人加入私人频道
1.生成邀请链接或二维码:如果您希望邀请他人加入您的私人频道,您可以通过生成邀请链接或二维码来邀请他们。这些链接或二维码可以让被邀请人直接加入您的频道。
2.发送邀请链接或二维码给他人:将生成的邀请链接或二维码发送给想要邀请的人。您可以通过电子邮件、社交媒体或其他渠道将链接或二维码发送给他人。
3.被邀请人接受邀请并加入频道:被邀请人收到链接或二维码后,可以通过点击链接或扫描二维码来接受邀请并加入您的私人频道。
六、注意事项
1.确保使用真实身份创建频道:为了保护个人隐私和信息安全,建议您使用真实身份创建私人频道。这将有助于确保您与他人之间的交流更加真实可靠。
2.注意保护个人隐私和信息安全:在创建和使用私人频道时,请注意保护个人隐私和信息安全。不要将敏感信息泄露给他人,并确保您的账户安全可靠。同时,也要注意遵守Telegram平台的使用规则和政策,确保您的行为符合平台要求。



























 Cloudflare
Cloudflare Ollama
Ollama OpenAI
OpenAI OpenClash
OpenClash