主流的视频AI大模型(如Stable Video Diffusion、Sora-like模型或其他生成式视频模型)的部署需要考虑计算资源需求、推理延迟、用户交互体验以及是否需要离线运行等因素。以下是部署主流视频AI大模型的建议,以及适用的UI界面选项。
部署主流视频AI大模型的策略
-
硬件选择与优化
-
GPU/TPU支持: 视频AI大模型通常需要高性能GPU(如NVIDIA A100、H100)或TPU来加速推理。部署时需确保硬件支持FP16或INT8量化以降低内存占用。
-
分布式部署: 对于大规模推理,可以使用多GPU集群,通过框架如PyTorch Distributed或Horovod实现并行处理。
-
模型压缩: 使用量化(如4-bit或8-bit)、剪枝或蒸馏技术(如DistilBERT思路)减少模型体积,提升推理速度。
-
本地 vs 云端:
-
本地部署适合隐私敏感场景,使用高性能桌面(如NVIDIA DGX)或边缘设备。
-
云端部署(如AWS、GCP、Azure)适合需要弹性扩展的场景,可通过API提供服务。
-
-
-
软件框架
-
TensorFlow Serving: 适合TensorFlow模型,提供高性能服务,支持模型版本管理和负载均衡。
-
PyTorch Serve: 适用于PyTorch模型,易于集成视频预处理和后处理逻辑。
-
Hugging Face Diffusers: 如果使用开源视频生成模型(如Stable Video Diffusion),Diffusers库提供预训练模型和推理优化。
-
BentoML: 轻量化部署框架,支持多模态模型,适合快速构建API服务。
-
-
部署方式
-
API服务: 将模型封装为RESTful或gRPC API,用户通过HTTP请求上传视频或文本提示,获取生成结果。
-
容器化: 使用Docker将模型、依赖和UI打包,确保环境一致性。结合Kubernetes实现自动扩展和负载均衡。
-
实时流处理: 如果需要实时视频生成,可结合FFmpeg处理视频流,集成到推理管道中。
-
批处理: 对于非实时需求(如批量生成视频),可通过任务队列(如Celery)调度推理任务。
-
-
优化推理延迟
-
批处理(Batching): 支持动态批处理以提高GPU利用率。
-
缓存机制: 对常用提示或中间结果缓存(如使用Redis),减少重复计算。
-
Flash Attention: 如果模型基于Transformer架构,可使用优化注意力机制降低内存和时间开销。
-
-
监控与维护
-
使用Prometheus和Grafana监控推理延迟、GPU利用率和错误率。
-
通过MLflow或Kubeflow跟踪模型版本和性能,确保可回滚到旧版本。
-
适用UI界面选项
以下是部署视频AI大模型时常用的UI框架,适用于不同用户需求:
-
Gradio
建造-
特点: Python库,快速构建交互式Web界面,支持视频上传和结果展示。
-
视频支持: 内置视频输入/输出组件,可直接处理视频文件或流。
-
部署方法:python
import gradio as gr def generate_video(prompt): # 调用视频AI模型 video_result = your_video_model(prompt) return video_result iface = gr.Interface(fn=generate_video, inputs="text", outputs="video") iface.launch() -
适用场景: 快速原型验证、演示视频生成效果。
-
优点: 简单易用,支持实时交互。
-
局限: 功能较基础,复杂UI需额外开发。
-
-
Streamlit
-
特点: Python框架,适合数据驱动应用,易于展示视频生成结果。
-
视频支持: 通过st.video展示生成视频,结合st.file_uploader支持上传。
-
部署方法:python
import streamlit as st def generate_video(prompt): return your_video_model(prompt) prompt = st.text_input("输入提示") if st.button("生成"): video = generate_video(prompt) st.video(video)import streamlit as st 定义 -
适用场景: 数据科学家展示模型效果,或构建简单演示工具。
-
优点: 开发迅速,与Python生态集成好。
-
局限: 实时性较弱,复杂交互需定制。
-
-
Open WebUI
打开 WebUI-
特点: 开源Web界面,适合多模态AI,支持离线运行,类似ChatGPT风格。
-
视频支持: 通过插件可扩展视频输入/输出功能。
-
部署方法:
-
Docker部署:docker run -d -p 3000:8080 ghcr.io/open-webui/open-webui:main
Docker部署: docker run -d -p 3000:8080 ghcr.io/open-webui/open-webui:main -
配置API连接到视频AI模型后端。
-
-
适用场景: 需要聊天式交互+视频生成的综合应用。
-
优点: 开源、可扩展、界面现代化。
-
局限: 视频支持需额外开发。
-
-
LobeChat
-
特点: 开源AI聊天界面,支持多模态(文本、语音、图像),可扩展到视频。
-
视频支持: 可通过后端API集成视频生成功能。
-
部署方法:
-
Docker部署:docker run -d -p 3210:3210 lobechat/lobechat
Docker部署: docker run -d -p 3210:3210 lobechat/lobechat -
配置视频模型API。
-
-
适用场景: 智能助手式应用,结合视频生成。
-
优点: 美观易用、支持多模态。
-
局限: 视频功能需后端支持。
-
-
自定义Web UI (Flask/Django + HTML5)
-
特点: 使用Flask或Django后端,结合HTML5和WebRTC实现完全定制化UI。
-
视频支持: 支持实时视频流处理、上传和播放。
-
部署方法:python
from flask import Flask, request, render_template app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def index(): if request.method == 'POST': prompt = request.form['prompt'] video = your_video_model(prompt) return render_template('result.html', video=video) return render_template('index.html') if __name__ == '__main__': app.run() -
适用场景: 专业项目,需要深度定制和复杂交互。
-
优点: 灵活性高,可集成复杂功能。
-
局限: 开发周期长。
-
选择建议
-
快速原型: Gradio 或 Streamlit,适合快速测试和展示。
-
多模态交互: Open WebUI 或 LobeChat,适合结合文本和视频的交互式应用。
-
大规模生产: 自定义Web UI + 云端部署,结合API和容器化,适合高并发和复杂需求。
-
具体模型适配: 如果使用Stable Video Diffusion等开源模型,推荐结合Hugging Face Diffusers和Gradio/Open WebUI快速部署。



 选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。
选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。

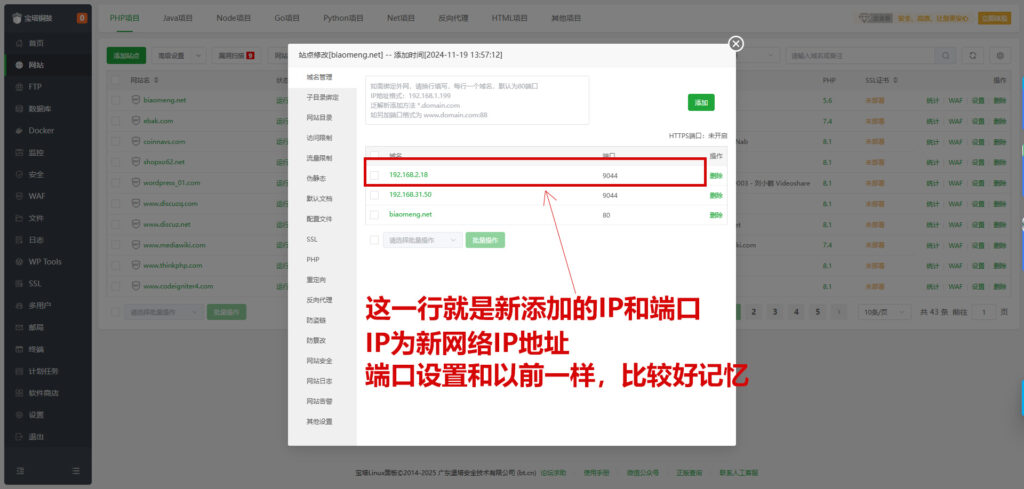 二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了
二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了


 Cloudflare
Cloudflare Ollama
Ollama OpenAI
OpenAI OpenClash
OpenClash







评论前必须登录!
立即登录 注册