对于音频AI大模型的UI部署,根据你的需求(例如是否需要用户友好的界面、是否支持多模态交互、是否需要完全离线运行等),有以下几种常见的UI框架和工具可供选择。这些工具适用于不同的场景,包括本地部署和与音频AI模型的集成。以下是一些推荐选项:
1. Open WebUI
1. 打开WebUI
1. 打开WebUI
-
特点: Open WebUI 是一个功能丰富、用户友好的自托管Web界面,特别适合与大型语言模型(LLM)和多模态AI集成。它支持Ollama等运行器以及OpenAI兼容的API,可以完全离线运行。
-
音频支持: 虽然本身不是专为音频设计的UI,但通过插件(如Pipelines框架),可以集成音频处理逻辑,例如语音转文本(STT)或文本转语音(TTS)。
-
部署方法:
-
通过Docker快速安装:docker run -d -p 3000:8080 ghcr.io/open-webui/open-webui:main
通过Docker快速安装: docker run -d -p 3000:8080 ghcr.io/open-webui/open-webui:main -
支持自定义API URL,可以连接到你的音频AI模型后端。
-
-
适用场景: 如果你的音频AI大模型需要一个类似ChatGPT的交互界面,并且你希望支持多模态(如文本+语音),这是个不错的选择。
-
优点: 开源、易于扩展、社区活跃。
-
局限: 需要一定的配置来适配音频功能。
2. Gradio
2. 建造
2. 建造
-
特点: Gradio 是一个Python库,专为机器学习模型设计,提供简单易用的Web界面。它天然支持音频输入和输出,非常适合部署音频AI模型。
-
音频支持: 内置音频组件,可以直接上传音频文件或通过麦克风录制音频,处理后返回结果(例如语音识别或生成音频)。
-
部署方法:
-
示例代码:python
import gradio as gr def process_audio(audio): # 假设这是你的音频AI模型处理函数 result = your_audio_model(audio) return result iface = gr.Interface(fn=process_audio, inputs="audio", outputs="text") iface.launch() -
可通过launch(share=True)生成公网链接,或本地运行。
-
-
适用场景: 快速原型开发、测试音频AI模型,或需要简单交互界面的场景。
-
优点: 简单易用、支持实时音频输入输出。
-
局限: 界面功能相对基础,复杂交互需要额外定制。
3. Streamlit
3.Streamlit
3.Streamlit
-
特点: Streamlit 是一个Python框架,用于快速构建数据驱动的Web应用。它支持自定义UI,适合展示音频AI模型的结果。
-
音频支持: 虽然没有内置音频输入组件,但可以通过st.audio展示音频文件,或结合第三方库(如pyaudio)实现音频录制和处理。
-
部署方法:
-
示例代码:python
import streamlit as st def process_audio(audio_file): # 调用音频AI模型 result = your_audio_model(audio_file) return result uploaded_file = st.file_uploader("上传音频", type=["wav", "mp3"]) if uploaded_file: result = process_audio(uploaded_file) st.write(result) -
运行:streamlit run your_script.py
运行: streamlit run your_script.py
-
-
适用场景: 需要展示音频处理结果(如语音识别、音频生成)的演示应用。
-
优点: 灵活性高、易于与Python生态集成。
-
局限: 实时音频交互需要额外开发。
4. LobeChat
-
特点: LobeChat 是一个开源的AI聊天界面,支持多模态交互(文字、语音、图片等),可以通过Ollama等工具与本地模型集成。
-
音频支持: 支持语音输入和输出,适合构建类似智能助手的应用。
-
部署方法:
-
使用Docker部署:docker run -d -p 3210:3210 lobechat/lobechat
使用Docker部署: docker run -d -p 3210:3210 lobechat/lobechat -
配置后端指向你的音频AI模型。
-
-
适用场景: 如果你的音频AI模型需要语音对话功能,LobeChat 是一个现成的解决方案。
-
优点: 高颜值界面、支持插件扩展。
-
局限: 更偏向聊天场景,音频处理需依赖后端支持。
5. Custom Web UI (基于 Flask/Django + HTML5)
5. Custom Web UI (基于Flask/Django + HTML5)
5. Custom Web UI (基于Flask/Django + HTML5)
-
特点: 如果现有框架无法满足需求,可以使用Flask或Django等后端框架,结合HTML5的前端技术(如Web Audio API)打造完全定制的UI。
-
音频支持: 支持实时音频录制、播放和处理,灵活性极高。
-
部署方法:
-
Flask 示例:python
from flask import Flask, request, render_template app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def index(): if request.method == 'POST': audio = request.files['audio'] result = your_audio_model(audio) return result return render_template('index.html') if __name__ == '__main__': app.run() -
前端HTML5录制音频并上传。
-
-
适用场景: 需要深度定制或与特定音频AI模型高度集成的场景。
-
优点: 完全可控、适合复杂需求。
-
局限: 开发成本较高。
选择建议
-
简单快速部署: 推荐 Gradio 或 Streamlit,适合快速验证音频AI模型。
-
多模态交互: 推荐 Open WebUI 或 LobeChat,适合需要语音+文本的场景。
-
完全定制: 选择 Flask/Django + HTML5,适合专业项目。
根据你的具体需求(例如是否需要实时语音交互、是否离线运行),可以进一步明确选择。如果你的音频AI大模型是基于开源模型(如Qwen2 Audio或Whisper),这些UI框架都可以通过API或本地调用与之集成。你可以告诉我更多细节(比如模型类型或功能需求),我可以帮你进一步优化建议!




 选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。
选择不同的客户端之前,首先需要确认该客户端是否支持节点即代理服务器提供的协议,如 v2rayN 支持 VMess、VLESS、Trojan、Socks、Shadowsocks、Hysteria2、Tuic 等代理协议,所以需要确认选择的客户端是否支持服务器提供的协议。

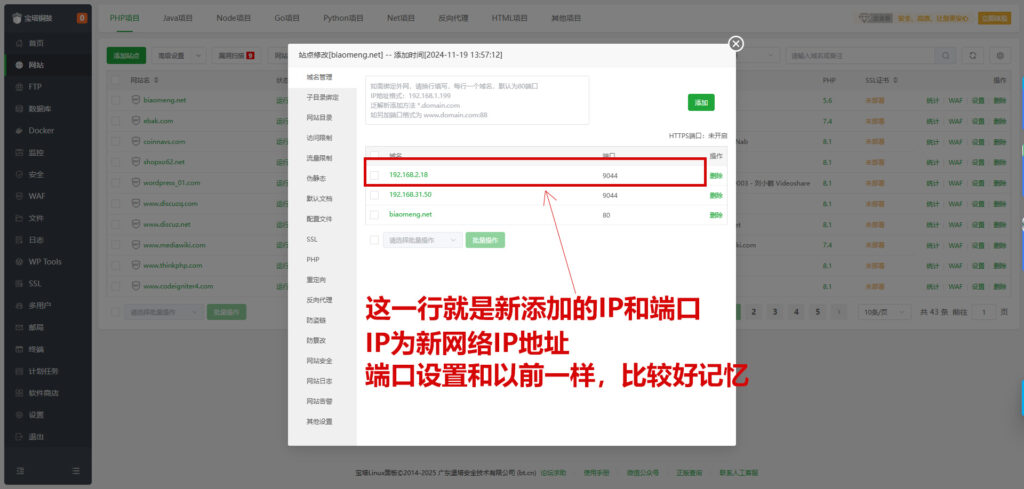 二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了
二、授权新IP客户端电脑
安装插件:IP配置工具
打开IP配置工具--SSH,添加需要授权登录的客户端IP地址
然后用客户端宝塔管理工具登录,就可以登录了


 Cloudflare
Cloudflare Ollama
Ollama OpenAI
OpenAI OpenClash
OpenClash







评论前必须登录!
立即登录 注册